




Example predictions for MNIST, KTH, BAIR, Cityscapes and KITTI datasets.
Abstract
Motion is an important cue for video prediction and often utilized by separating video content into static and dynamic components. Most of the previous work utilizing motion is deterministic but there are stochastic methods that can model the inherent uncertainty of the future. Existing stochastic models either do not reason about motion explicitly or make limiting assumptions about the static part. In this paper, we reason about appearance and motion in the video stochastically by predicting the future based on the motion history. Explicit reasoning about motion without history already reaches the performance of current stochastic models. The motion history further improves the results by allowing to predict consistent dynamics several frames into the future. Our model performs comparably to the state-of-the-art models on the generic video prediction datasets, however, significantly outperforms them on two challenging real-world autonomous driving datasets with complex motion and dynamic background.
Method Overview
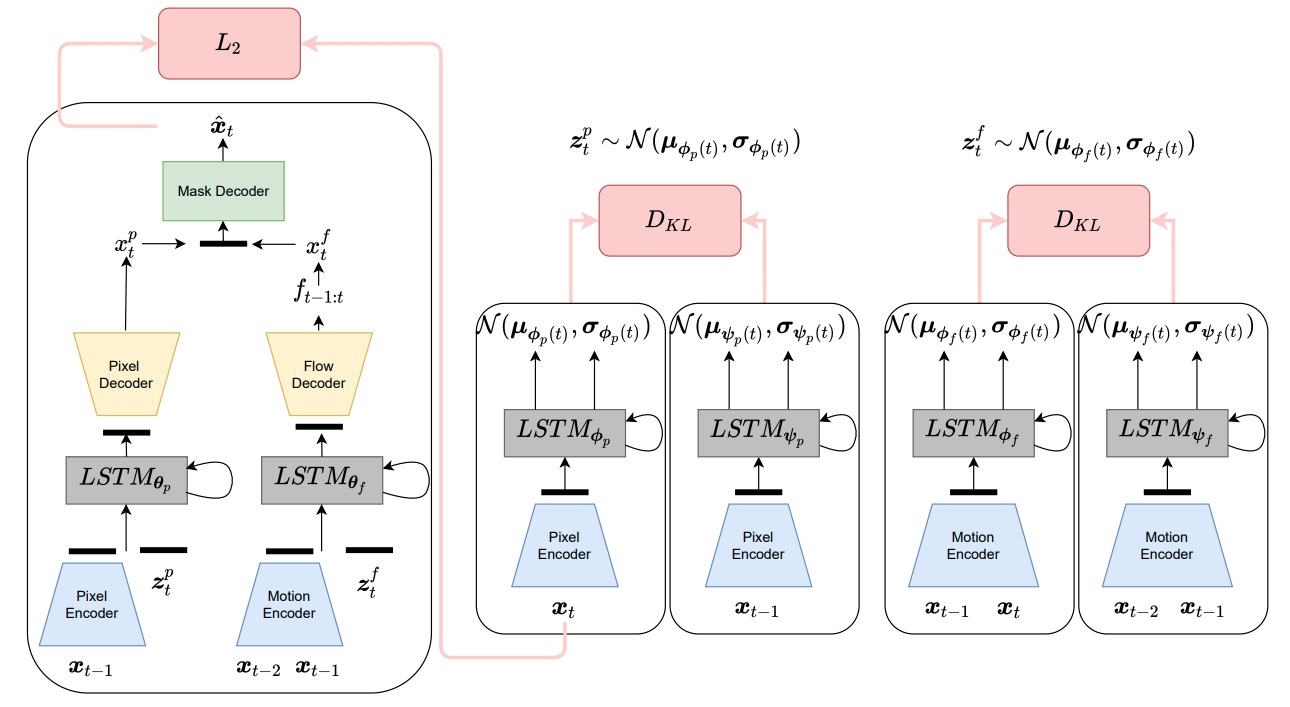
Instead of focusing on pixel space only, we also focused a more meaningful space by modelling the motion of the scene. We model the motion history explicitly by learning to predict the optical flow which is needed to go from the current frame to future frame besides predicting the future scene in the pixel space. At the end, we have two predictions, one coming from pixel prediction head, and the other one coming from optical flow warping, and we combine both predictions by predicting a mask to choose between these two predictions. The final prediction consists of best parts of both predictions.
[Code]
Results





Dynamic and Static Latent Variables

We provide a visualization of stochastic latent variables of the dynamic component on KTH using t-SNE. Here, we provide both the static and the dynamic components for a comparison. As can be seen from the Figure, static variables on the right are more scattered and do not from clusters according to semantic classes as in the dynamic variables on the left (and in the main paper). This shows that our model can learn video dynamics according to semantic classes with separate modelling of the dynamic component.
Paper

SLAMP: Stochastic Latent Appearance and Motion Prediction
Adil Kaan Akan, Erkut Erdem, Aykut Erdem and Fatma Guney
In ICCV, 2021.
@InProceedings{Akan2021ICCV,
author = {Akan, Adil Kaan and Erdem, Erkut and Erdem, Aykut and Guney, Fatma},
title = {SLAMP: Stochastic Latent Appearance and Motion Prediction},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2021},
pages = {14728-14737}
}
}Acknowledgements
We would like to thank Jean-Yves Franceschi and Edouard Delasalles for providing technical and numerical details of the baseline performances, Deniz Yuret and Salih Karagoz for helpful discussions and comments. Kaan Akan was supported by KUIS AI Center fellowship, Fatma Güney by TUBITAK 2232 International Fellowship for Outstanding Researchers Programme, Erkut Erdem in part by GEBIP 2018 Award of the Turkish Academy of Sciences, Aykut Erdem by BAGEP 2021 Award of the Science Academy..